Summary
This interpreter connects theory to implementation by converting a regex string into an AST, generating an NFA using Thompson’s construction, and simulating the automaton to determine whether input strings are accepted.
My Role
Individual developer. I designed the parser, implemented Thompson’s construction, built an interactive menu interface, and created automated tests to validate parsing, NFA generation, and simulation behavior.
The Challenge
The hardest part was building a pipeline where each stage is correct and composable: tokens → AST structure → Thompson NFA fragments → ε-closure simulation. Small mistakes in parsing precedence or ε-transition handling can cause the entire language acceptance check to fail.
Introduction & motivation
Regular expressions are widely used for searching, validation, and parsing, but their power comes from formal computation ideas. This project demonstrates how a regex can be treated as a formal language description and implemented through automata theory; specifically, by building an NFA and simulating it to recognize strings.
Theoretical foundations
Key idea
Every regular expression corresponds to a regular language, and every regular language can be recognized by a finite automaton. Thompson’s construction provides a practical algorithm for converting regex operators into NFA “fragments” connected by ε-transitions.
Why NFA (not DFA)
- NFAs are simpler to construct directly from regex structure.
- ε-transitions make it easy to combine sub-expressions (union, concat, star).
- Simulation can be implemented using ε-closures over sets of states.
Regex operators supported
- Union:
r|s - Concatenation:
rs(implicit) - Kleene star:
r* - Grouping:
(r) - Literals: alphanumeric characters
Parser design
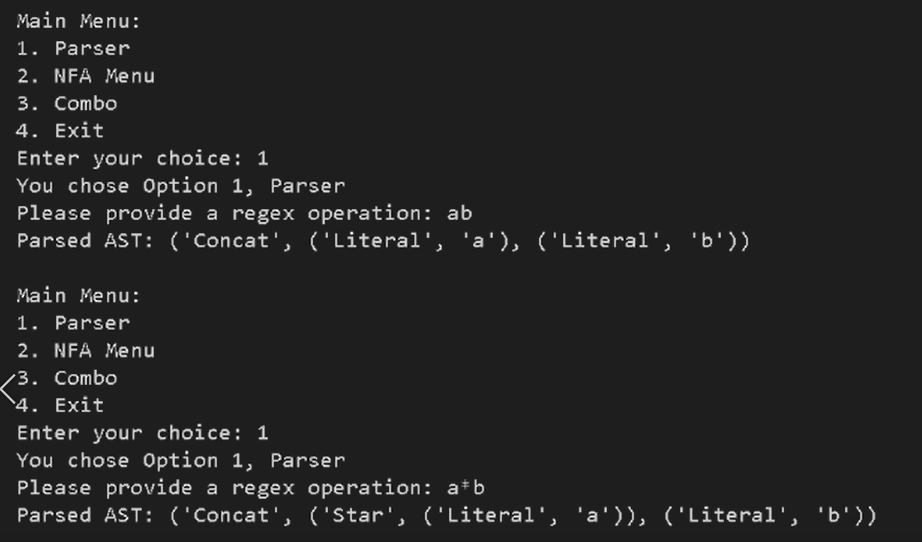
I implemented a recursive-descent parser to handle operator precedence and grouping. The parser builds an AST using a small grammar split into four functions (expression/term/factor/base). This structure makes precedence explicit: star binds tightest, then concatenation, then union.
Grammar (conceptual)
expression → term ( '|' expression )?term → factor+(until|or))factor → base ( '*' )?base → '(' expression ')' | literal
AST representation
The AST is represented as nested tuples to clearly show structure:
('Literal', 'a')('Star', subtree)('Concat', subtree1, subtree2, ...)('Union', left, right)
This format makes debugging and explanation easier in demos and tests.
Thompson’s construction (AST → NFA)
After parsing, the AST is converted into an NFA by recursively constructing NFA fragments for each operator and connecting them with ε-transitions. Each fragment has a single start and accept state.
Construction rules
- Literal: create two states with a labeled transition.
- Concat: connect accept of left fragment to start of next fragment via ε.
- Union: new start ε-splits to each option; each option ε-joins into a new accept.
- Star: new start/accept with ε-loops to allow zero or more repetitions.
Why ε-transitions matter
ε-transitions allow the automaton to change state without consuming input, which is essential for composing fragments while preserving correct language behavior, like in the case of union branching and star repetition.
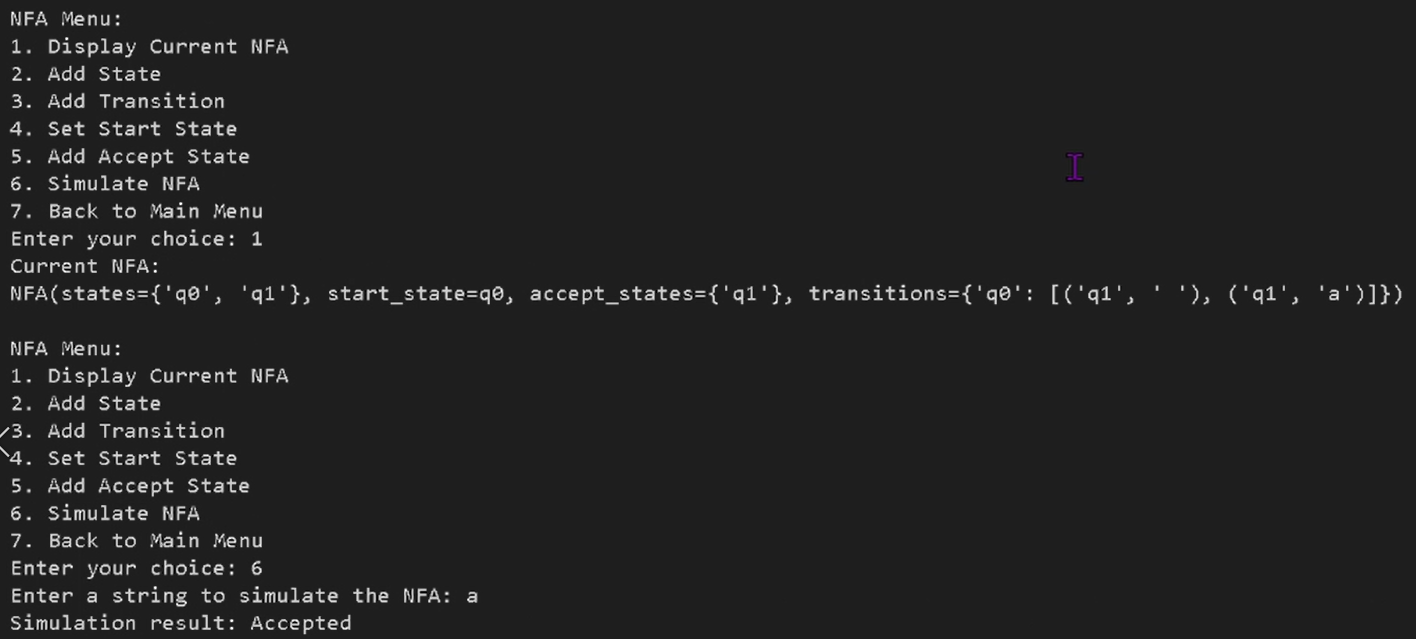
NFA simulation
The simulator evaluates whether a string is accepted by tracking a set of “current” states rather than a single state. At each input character, it transitions to the next set of states and repeatedly expands via ε-closure.
High-level algorithm
- Start from ε-closure(start state).
- For each character in the input string:
- Find all transitions matching the character from current states.
- Move to those destination states.
- Expand via ε-closure again.
- Accept if any current state is an accept state at end of input.
What makes this tricky
- Correct ε-closure expansion without infinite loops
- Maintaining sets of states (not single paths)
- Ensuring transitions match parser intent (precedence + grouping)
Testing & validation
I used unit tests to validate parsing and NFA behavior across different operator combinations and edge cases. Testing focused on ensuring that the AST structure matched expected precedence and that the resulting NFA accepted the correct language.
- Parsing tests for grouping and precedence (
*vs concat vs|) - NFA acceptance tests using representative strings
- Negative tests for invalid input (e.g., unmatched parentheses)
Edge cases handled
- Empty regex rejected
- Unmatched parentheses detected
- Unexpected tokens rejected
- Alphanumeric literal enforcement
Results, limitations, & next steps
What works
- Reliable parsing for supported operators and grouping
- Correct Thompson NFA construction for AST structure
- Simulation with ε-closures to validate acceptance
Current limitations
- Literal tokens are restricted to alphanumeric characters
- Advanced regex features (character classes, +, ?, escapes) are not implemented
- NFA visualization is textual (diagram export would be a strong upgrade)
Next improvements
- Add additional operators (
+,?) and escape handling - Support richer tokens (punctuation, whitespace rules, character classes)
- Generate NFA diagrams automatically (Graphviz export)
- Expand CLI into a small teaching tool for automata theory
Project artifacts
These materials document the implementation, theory, and walkthrough:
- Final paper: full technical write-up and design rationale
- Presentation + script: structured walkthrough of the pipeline and results
- Demo video: live run of parsing, NFA build, and simulation
- GitHub repository: source code and tests
Links
Open the repo, paper, and demo materials:
Reflection
What I learned
This project strengthened my ability to translate theory into working software. I gained hands-on experience designing a recursive-descent parser, building an AST, and implementing Thompson’s construction and ε-closure simulation. The biggest takeaway was learning how small correctness details like precedence, grouping, and ε-transitions, directly determine whether the implementation recognizes the intended language.
What I’d do next
- Add richer token support and more regex operators
- Export and visualize NFAs automatically
- Expand the menu into a small educational toolkit for automata concepts